
나만의 개발 로그 | 고민 로그
데이터, 0과 1 본문
비트(bit) : 0과 1을 표현하는 가장 작은 정보 단위
- n비트로 2의 n승만큼의 정보 표현 가능
- 프로그램은 수많은 비트로 이루어져 있음
- 1바이트(1byte) : 8비트(8bit)
- 1킬로바이트(1kB) : 1000바이(1,000byte)
- 1메가 바이트(1MB) : 1000킬로바이트 (1,000MB)
- 등등..
→ 1024개씩 묶은 단위는 kiB MiB GiB 등 따로 있음. 예전에는 구분 안했는데 요새는 구분하는 추새
워드(word)
- CPU가 한번에 처리할 수 있는 정보의 크기 단위
- 풀 워드 : 워드 크기
- 하프 워드 : 워드의 절반 크기
- 더블 워드 : 워드의 2배 크기
0과 1로 숫자 표현 하기
이진법(binary) : 0과 1로 숫자 표현
- 숫자가 1 넘어가면 자리 올림
- 우리가 일상적으로 사용하는 십진법(decimal)은 9 넘어가면 자리 올림
- ex) 십진수 7 = 이진수 111
- 컴퓨터는 십진수 (2+8)에 대해 이진수 (10+1000)으로 이해하는 것
- 보통 밑의첨자2를 넣어서 이진수라고 표기
0과 1로 음수 표현 하는 법 : 2의 보수
- 어떤 수를 그보다 큰 2의 n승에서 뺀 값
- 만약 이진수 11을 음수로 표현하면 01임
- 이진수 11보다 큰 2의 n승은 이진수 100임. 이때 100 - 11 = 01
- 쉽게 구하는 법 : 모든 0과 1을 뒤집고 1을 더한다
- 이진수 11의 모든 0과 1을 뒤집는다.
- 이진수 11 → 이진수 00
- 2번에 1을 더한다.
- 이진수 01이 된다.
- 문제 : 만약 1011을 음수로 바꾸면 0101이 되는데 십진수 5와 어떻게 구분하는가?
- cpu 내부에는 플래그라고 하는 특별한 레지스터가 있음
- 모든 숫자는 플래그를 달고 다님
- 이 플래그에다가 양수인지 음수인지를 표시돼있음
- 그냥 모든 숫자는 양수인지 음수인지를 뜻하는 깃발 들고 다닌다고 이해
십육진법
- 이진법으로는 숫자의 길이가 너무 길어지기 때문에 십육진법도 사용함
- 예를 들어 십진수 32를 이진수로 표현하려면 100000
- 너무 길어지기 때문에 십육진법도 많이 사용
- 숫자 15 넘어가는 시점에 자리 올림
- 0~9 그리고 ABCDEF로 표현
- 밑의첨자 16 혹은 0x로 십육진수라고 표기해줌
- ex) 0x00ffffff
왜 이진수와 십육진수를 사용하는가?
이진수와 십육진수가 서로 변환하기 쉽기 때문
십육진수의 1개를 이진수 4개라고 생각하고 변환 하면 됨
반대는 이진수 4개를 십육진수 1개라고 생각하고 변환 하면 됨
0과 1로 문자 표현 하기
문자 집합과 인코딩
문자 집합(character set)
- 컴퓨터가 이해할 수 있는 문자의 모음
인코딩(encoding)
- 코드화하는 과정
- 문자를 0과 1로 이루어진 문자 코드로 변환하는 과정
디코딩(decoding)
- 코드를 해석하는 과정
- 0과 1로 표현된 문자 코드로 문자로 변환하는 과정
아스키 코드
- 초창기 문자 집합 중 하나
- 알파벳, 아라비아 숫자, 일부 특수 문자 및 제어 문자(엔터, 백스페이스 등) 표현
- 7비트로 하나의 문자 표현
- 8비트 중 1비트는 오류 검출을 위해 사용 되는 패리티 비트(parity bit)
- 즉 2의 7승만큼의 문자를 아스키 코드로 표현 가능
- 간단한 인코딩(문자에 부여된 값을 그대로 사용하면 되니)
- 문제점 : 한글을 포함한 다른 언어 문자, 다양한 특수 문자 표현 불가능!!!!
- why? 7비트로 하나의 문자를 표현하기 때문
- 128개보다 많은 문자 표현할 수 없다.
한글 인코딩 : 완성형 vs 조합형 인코딩
- 한글을 위한 인코딩이 필요
- 한글의 특징
- 초성, 중성, 종성의 조합으로 이루어진 한글… 알파벳 이어 쓰면 완성되는 영어와 다름
- 완성형 인코딩 방식과 조합형 인코딩 방식이 존재
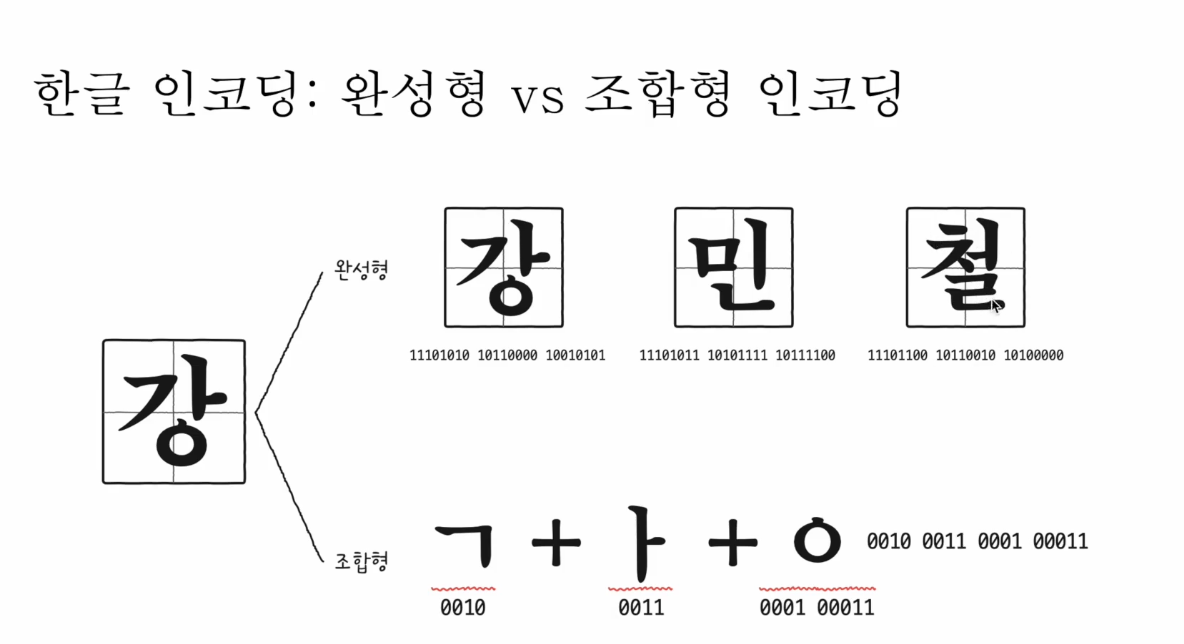
완성형은 글자마다 고유 코드 부여
조합형은 초성, 중성, 종성의 자음과 모음마다 고유 코드 부여해서 조합
ex)

- EUC-KR
- 완성형 인코딩
- 글자 하나 하나에 2바이트 크기의 코드 부여
- 2바이트 == 16비트 == 4자리 십육진수로 표현
- 2300여개의 한글 표현 가능
- 여전히 모든 한글 표현 불가능.. 쀏,뙠,휔같은 한글 표현 불가능
- 따라서 특이한 글자는 특수기호로 표기되는 일종의 버그 발생!
- 여전히 모든 한글 표현 불가능.. 쀏,뙠,휔같은 한글 표현 불가능
- 이렇게 언어별 인코딩을 국가마다 하게 되면 복잡해짐
유니코드 문자 집합과 uft-8
- 유니코드
- 통일된 문자 집합
- 한글, 영어, 화살표 같은 특수 문자, 이모티콘까지 가능
- 현대 문자 표현에 있어서 매우 중요한 위치
- 유니코드의 인코딩 방식
- utf-8, utf-16, utf-32
- U+219C 이런식으로 유니코드 문자에는 고유한 16진수 값 부여돼있음 → 유니코드 코드포인트라고 함
- 이 유니코드 코드포인트를 그대로 문자인코딩 값으로 사용하는게 아니라, 유니코드 하나 하나에 부여된 이 값을 어떤 방식으로 지지고 볶아서 컴퓨터가 이해하는 0과 1로 만드는 가에 따라 인코딩 방식이 나뉜다.
- utf-8 인코딩
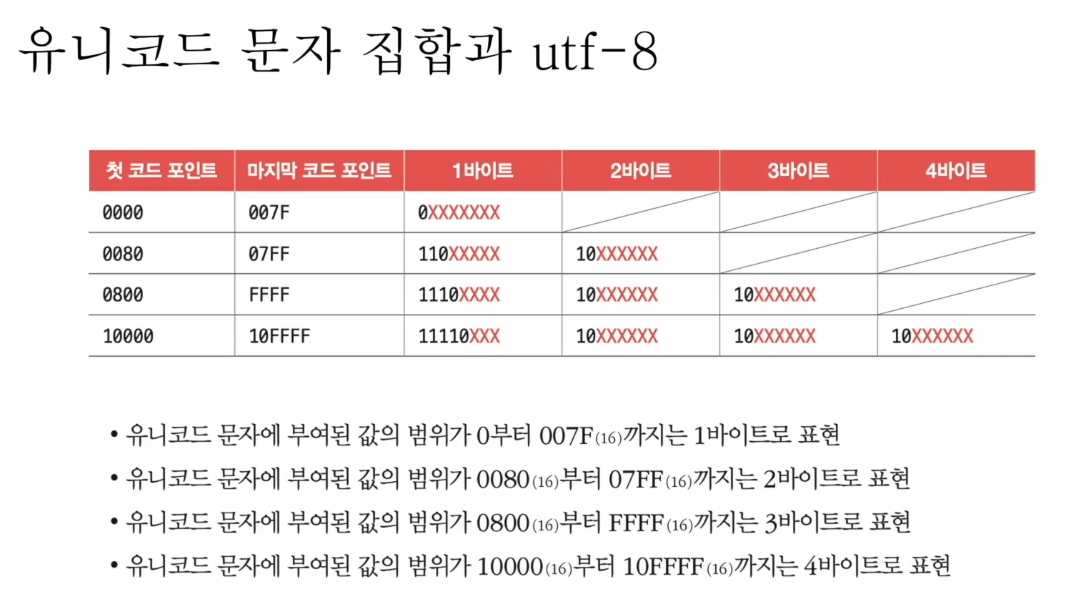
- UTF(Unicode Transformation Format) == 유니코드 인코딩 방법
- 가변 길이 인코딩 : 인코딩된 결과가 1바이트 ~ 4바이트 중 아무거나 될 수 있음
- 인코딩 결과가 몇 바이트가 될지는 유니코드에 부여된 값에 따라 다름
- 유니코드에 주어진 코드 포인트 범위에 따라 형식에 맞게 넣어주면 인코딩
'혼자 공부하는 컴퓨터구조+운영체제' 카테고리의 다른 글
| 메모리와 캐시 메모리 (0) | 2023.09.10 |
|---|---|
| cpu의 성능 향상 기법 (0) | 2023.09.09 |
| CPU의 작동 원리 (1) | 2023.09.05 |
| 명령어 (0) | 2023.08.28 |
| 컴퓨터 구조 (0) | 2023.08.16 |
Comments