
나만의 개발 로그 | 고민 로그
Web Crawling 및 OpenSearch 사용기 본문
개인 과제로
파이썬을 통해 크롤링하고 수집한 데이터를 오픈서치 인덱스로 저장 및 활용하여 시각화하는 작업을 진행했다.
크롤링도 정적 크롤링과 동적 크롤링이 있었는데 request를 활용한 정적 크롤링 방식으로 진행했다.
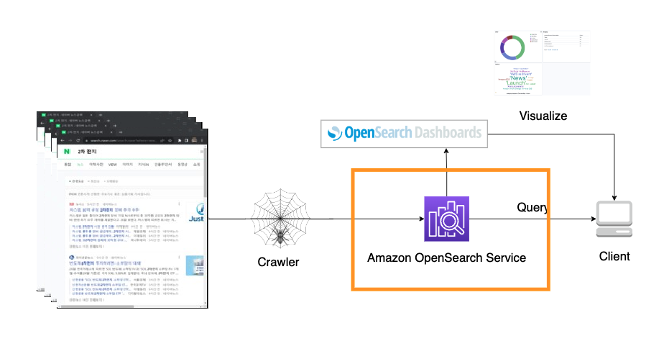
이렇게 네이번 뉴스 검색 데이터를 aws opensearch 서버로 인덱스 저장 및 활용하는 방식으로 만들었다.

네이버 뉴스 Url 에서 가변적으로 변하는 부분을 변수로 받아서 입력 하게 하고

페이지별 뉴스가 보이는 곳에서는 뉴스 본문이 짤리기 때문에 네이버뉴스 링크를 타고 세부 기사 항목으로 들어간 뒤에

제목, 본문, 언론사, 날짜같은 데이터들을 수집했다.

위처럼 저장을 하면 인덱스 작업을 거친 뒤 오픈서치 서버에 json 형태로 저장이 된다.(하단 형태)

* 오픈서치란?
오픈서치는 대표적인 검색엔진인 Elastic Search를 포크 해서 아마존에서 만든 오픈소스 검색엔진이다.
엘라스틱서치가 7.10버전 까지만 100%오픈소스로 제공하고
이후 버전은 SSPL(Server Side Public License)와 유료버전 라이센스로 나뉘어져서 제공을 하기 때문에
상업적으로 사용하면 소스 코드 공개의무가 생겼다. 이에 오픈서치가 대안으로 개발된 것이다.
아직까지는 엘라스틱서치와 성능상 큰 차별점은 없는 것 같다.
엘라스틱서치는 한국어 형태소 분석기로 노리를 밀지만 오픈서치는 은전한닢을 민다는 것? 하지만 노리나 은전한닢이나 기반이 동일하니..
* 데이터 저장 구조
오픈서치는 데이터를 역색인 구조로 저장한다.
기존 RDBMS에서 문서를 먼저 찾고, 그 안에서 단어를 찾는 방식이라면
역색인 구조는 단어를 먼저 찾고 그 이후에 문서를 찾아내는 방법이다.
예를 들어서
1번 문서 : 주말이 왔으면 좋겠다.
라고 저장되는 방식이 익숙한 방식인데
역색인 구조같은 경우는
주말이 : 1번 문서
왔으면 : 1번 문서
좋겠다 : 1번 문서
이런식으로 단어별로 저장돼 있는 문서를 바로 바로 찾을 수 있는 구조이다.
물론 이렇게 역색인 구조로 인덱스화 한다고해서 검색기능이 끝나는 것은 아니다.
가장 중요한 형태소 개념이 있다!
예를 들어

이렇게 기술특례상장이란 제목이 들어간 자료를 검색하고 싶을 때 특례라고만 검색하면 검색이 안된다.
따로 형태소 분석기를 정하지 않으면 역색인시에 공백을 기준으로 저장해서 '기술특례상장'이라는 단어를 기준으로 저장하기 때문이다.
밑에 케이스도 마찬가지다.

뛰다 라고 검색을 했을 때 뛰는 뛰어오른 이런식으로 비슷한 의미의 단어가 나오는 것이 고객들이 바라는 검색기능일 것이다.
이런걸 가능하게 해주는 것이 바로 형태소 분석기다!

예를 들어서 아버지가 방에 들어가신다라는 문장이 있다면
이거를 아버지/가/방/에/들어가/신다 이런식으로 품사를 분석하고 나눠서 저장해줄 수 있게 도와주는 것이 바로 형태소 분석기다.
특히나 우리나라 말은 복잡하기 때문에 한국어 형태소 분석기가 필수다.
오픈서치에서는 은전한닢 형태소를 밀고있기 때문에 저런식으로 은전한닢 형태소를 바탕으로 색인 작업을 진행했다.
엘라스틱서치라면 노리 형태소를 쓰면 된다..!
밑에는 한국어 형태소 분석기 적용 전후의 차이다
같은 쿼리를 날리는데도 결과가 다르다
바뀐 것은 한국어 형태소 분석기 적용 유무 뿐이다.
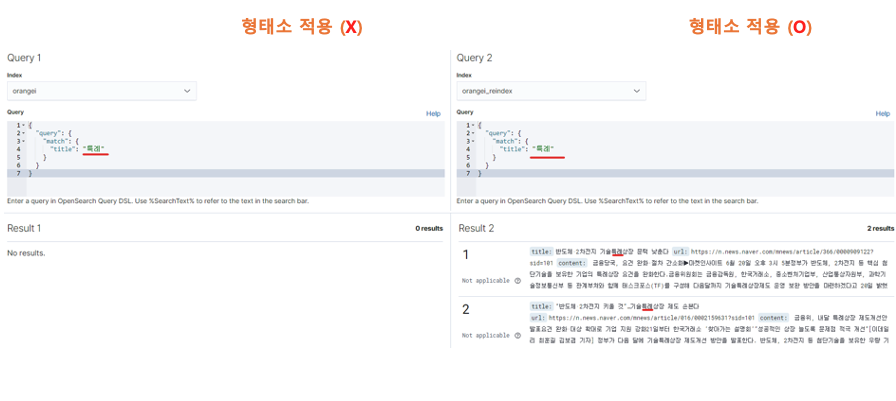
특례라고만 검색해도 이제는 기술특례사장같은 복합명사들도 척척 나온다.
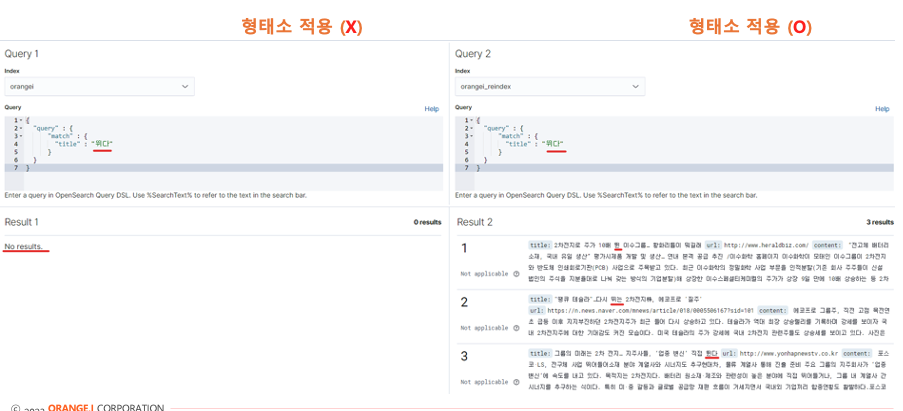
마찬가지로 뛰다라고만 검색해도 비슷한 의미의 뛰는 뛴 같은 단어들이 들어간 데이터를 찾아준다
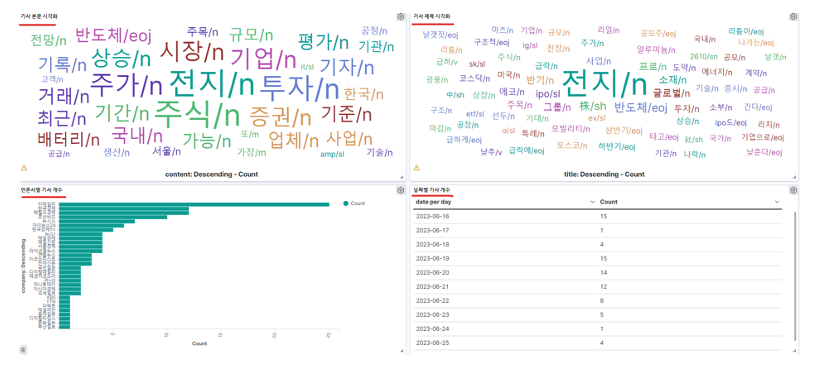
키바나 시각화를 이용한다면 위와 같이 데이터를 편하게 볼 수도 있다.
아무래도 기사 본문이나 제목같은 경우 형태소 단위로 분석을 해야 의미가 있기 때문에
field data를 true로 설정 하게 됐고, 그 때문에 무의미한 단어가 많아서 일일이 필터링을 해줘야 했다.
카테고리나 태그처럼 형태소로 쪼갤 필요 없이 하나의 완전한 단어들을 대상으로 시각화하면 굉장히 깔끔하게 유의미한 데이터 추출이 가능할 것 같다.
* 소감
크롤링 :
- 데이터 보호나 서버 부하를 줄이기 위해 크롤링 기능을 막아두는 곳들이 많다. 이번엔 Http 요청 헤더같은걸 변경해서 우회했는데 만약 상용화 서비스를 한다면 고려할 게 많을 것 같다고 느꼈다.
OpenSearch:
장점
- 표준 RESTful API를 제공하기 때문에 다양한 플랫폼에서 활용하기 좋은 것 같다.
- 분산 처리 구조를 가지고 있어서 데이터베이스 서버 확장 시에 용이할 것 같다.
단점
- 만들어진 지 얼마 안된 소프트웨어인만큼 국내 레퍼런스가 별로 없다는 것.
- 지금은 ElasticSearch와 갈라진 지 얼마 되지 않아서 ElasticSearch 자료를 참조하면 되지만 시간이 지날수록 차이가 커질텐데 추후 레퍼런스를 찾기 힘들 것 같다.
- 오픈서치를 썼지만 책도 엘라스틱 서치 실무가이드라는 책을 봤고, 엘라스틱 관련 레퍼런스를 많이 본 것 같다. 오픈서치에 대한 지식은 공식 가이드 문서 정도..
* 슬픈 후기

공식 가이드를 따라하면서 서버 설정을 고사양으로 하는 바람에 요금이 6만5천원이 청구됐다!!!!
며칠 돌렸더니 예상비용이 50달러로 뜨길래 서둘러 서버를 끄고
프리티어로 지원해주는 t3.small로 새로 만들었지만 너무 늦었던 것 같다
설정을 세세하게 검사 하고 요금 부분은 꼭 봐야겠다는 깨달음을 얻을 수 있는 좋은 기회였다..
아 aws opensearch service는 시간당 계산이 된다!!


'웹 개발' 카테고리의 다른 글
| 카프카(Kafka) (0) | 2023.08.19 |
|---|---|
| Postman에서 AccessToken 자동 입력하기 (0) | 2023.07.23 |
| 체크 예외, 언체크 예외 (0) | 2023.05.27 |
| Redis를 활용한 Cache 기능으로 조회 성능 개선 (1) | 2023.04.21 |
| AOP 활용하여 컨트롤러 메소드 실행시간 측정 (1) | 2023.04.14 |


